Grok 4.20 Non-Hallucination rate improved to even higher than previous highest Just days ago, it hit a record-breaking 78% Non-Hallucination Rate - already #1 in the world, smoking Claude Opus 4.6 (max), Gemini 3.1, GPT-5.4 (xhigh), and every other major model Now, it just pushed that number even higher to 83% While every other AI confidently makes up stuff and fabricate answers it doesn't know - Grok simply says "I don't know"
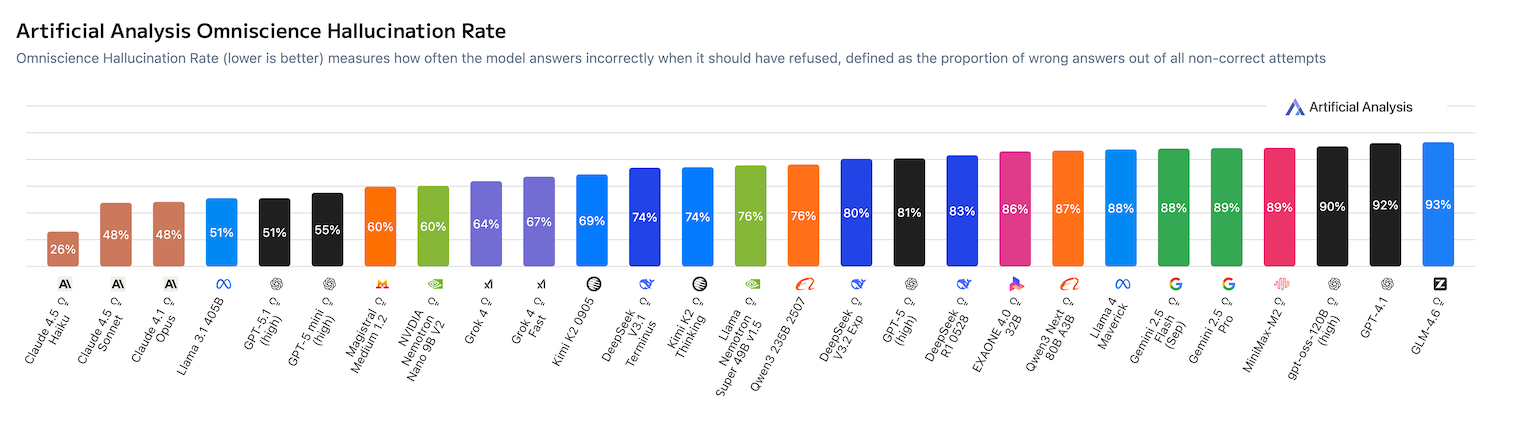
Bar chart titled 'Artificial Analysis Omniscience Hallucination Rate' showing hallucination/non-hallucination performance across many LLMs. It visualizes the AA‑Omniscience benchmark results where Grok 4.20 appears among the models with a low hallucination rate (i.e., high non‑hallucination), supporting the reported 78% → 83% non‑hallucination figures that Artificial Analysis published for Grok 4.20 builds.
Source: Artificial Analysis
Research Brief
What our analysis found
xAI's Grok 4.20, rolled out in a public beta-to-GA window around March 10–19, 2026, has generated significant buzz after posting what multiple outlets describe as a record-breaking 78% non-hallucination rate on Artificial Analysis's AA-Omniscience benchmark — a test designed to measure knowledge reliability by rewarding correct answers, penalizing hallucinations, and imposing no penalty for refusals. Separately, the model reportedly scored approximately 82.9–83% on IFBench, an instruction-following benchmark that evaluates precise task execution across 58 tasks. Both figures were widely cited together in March and April 2026 coverage from outlets including WinBuzzer, TokenCost, Doolpa, and PopularAITools.
A viral tweet now claims Grok 4.20 pushed its "non-hallucination rate" from 78% to 83%, framing the jump as a single metric climbing higher. However, research indicates the 78% figure comes from AA-Omniscience (hallucination measurement) while the 83% figure comes from IFBench (instruction-following measurement) — two entirely different benchmarks maintained by different organizations measuring different model behaviors. The tweet appears to conflate these two scores into one narrative of improvement on a single hallucination metric.
Adding further complexity, an independent leaderboard snapshot from BenchLM dated April 8, 2026 lists Qwen3.6 Plus at 75.8% as the IFBench leader and does not show Grok 4.20 at 83% on its public page, suggesting discrepancies across aggregators. Meanwhile, Reddit user reports after the Grok 4.20 rollout describe mixed real-world performance, with some users noting degraded instruction-following after updates — a reminder that benchmarks capture only a snapshot and live model behavior can shift with ongoing tweaks by xAI.
Fact Check
Evidence from both sides
Supporting Evidence
78% AA-Omniscience score is well-documented
Multiple independent outlets including WinBuzzer, Doolpa, and TokenCost cite Artificial Analysis's Omniscience benchmark as showing Grok 4.20 achieving a 78% non-hallucination rate, described as the highest among major models at the time of reporting in March 2026.
83% IFBench score is also widely reported
TokenCost's benchmark aggregation page for Grok 4.20 explicitly lists an IFBench score of approximately 83%, labeling it a number-one result in instruction following. PopularAITools and other tech outlets repeated this figure during the same reporting window.
Grok 4.20 topped the AA-Omniscience leaderboard
Coverage from March 2026 consistently describes Grok 4.20 as the top-performing model on the Artificial Analysis hallucination benchmark, outperforming competing models from Anthropic, Google, and OpenAI on that specific evaluation.
AA-Omniscience methodology rewards refusal over fabrication
Artificial Analysis confirms its Omniscience metric penalizes hallucinations but imposes no penalty for a model saying "I don't know," which aligns with the tweet's characterization that Grok opts to refuse rather than fabricate answers.
Contradicting Evidence
The tweet conflates two entirely different benchmarks
The 78% figure comes from AA-Omniscience (measuring hallucination tendency) while the 83% figure comes from IFBench (measuring instruction-following precision). These are maintained by different organizations and test fundamentally different model behaviors. Presenting 83% as an improved "non-hallucination rate" is factually incorrect according to TokenCost and Artificial Analysis, which label the metrics separately and clearly.
IFBench leaderboard discrepancies raise questions
A BenchLM snapshot from April 8, 2026 lists Qwen3.6 Plus as the IFBench leader at 75.8% and does not display Grok 4.20 at 83%, suggesting the claimed score may come from private runs, different benchmark versions, or selective aggregator coverage rather than a universally verified public result.
Real-world user experience contradicts benchmark superiority
Reddit discussions following the Grok 4.20 rollout include reports of degraded instruction-following and unexpected behavioral oddities, with xAI reportedly continuing to tweak the model after its benchmarked release — meaning the snapshot scores may not reflect the model users actually interact with.
Secondary reporting lacks primary verification
Much of the coverage cites benchmark results without linking to raw leaderboard tables or downloadable test logs, creating a telephone-game dynamic where social media posts like this tweet can further distort already loosely sourced numbers.
Report an Issue
Found something wrong with this article? Let us know and we'll look into it.