GPT-5.5 (medium) is tied for SOTA on Artificial Analysis. GPT-5.5 (high) and GPT-5.5 (xhigh) are meaningfully ahead. xhigh is the first model to break the 50's https://t.co/vmDhaKy5eL
)](https://cdn.sanity.io/images/6vfeftx9/articles/9052d745e6337cd4369bde9219bcf511bebec944-4644x1551.png?auto=format&w=1200)
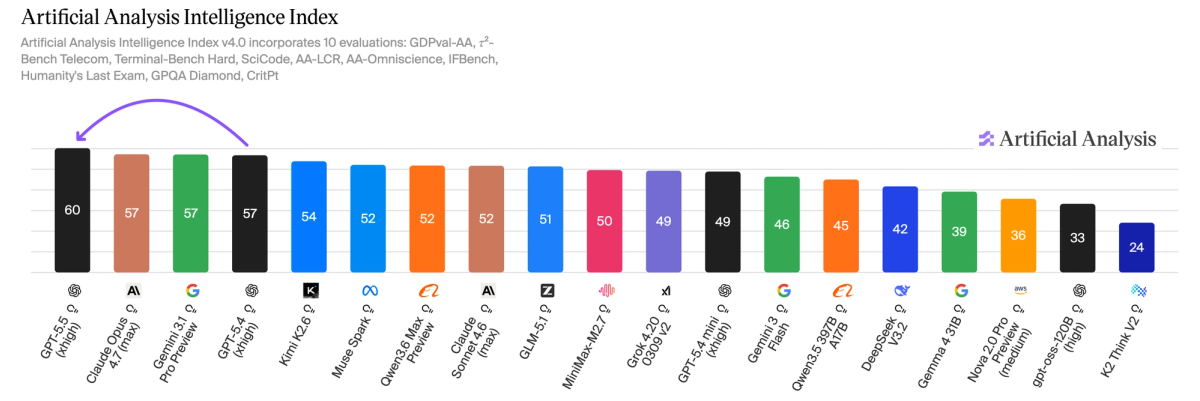
Bar-chart leaderboard from Artificial Analysis (April 23, 2026) showing the Artificial Analysis Intelligence Index: GPT-5.5 (xhigh) at 60 leading the board, GPT-5.5 (medium) at 57 (tied with others), and GPT-5.5 (high) positioned meaningfully ahead of medium—directly illustrating the tweet's claims about relative scores and xhigh breaking the 50s. ([cdn.sanity.io](https://cdn.sanity.io/images/6vfeftx9/articles/9052d745e6337cd4369bde9219bcf511bebec944-4644x1551.png?auto=format&w=1200))
Source: Artificial Analysis
Research Brief
What our analysis found
OpenAI released its GPT-5.5 model family on April 23, 2026, and the results on the Artificial Analysis Intelligence Index v4.0 — a composite benchmark aggregating ten evaluations across mathematics, science, coding, and reasoning — mark a notable leap in frontier AI performance. GPT-5.5 (xhigh) achieved a score of 60, making it the first model to break out of the 50s range on the index and surpassing the previous state-of-the-art score of 57, which was shared by GPT-5.4 (xhigh), Claude Opus 4.7 (max), and Gemini 3.1 Pro Preview. GPT-5.5 (high) followed closely at 59, while GPT-5.5 (medium) matched the prior leaders at 57, effectively tying for the previous SOTA at a fraction of the cost.
The cost dynamics are particularly striking. Although per-token pricing for GPT-5.5 has doubled compared to GPT-5.4 — now $5 per 1M input tokens and $30 per 1M output tokens — a roughly 40% reduction in token usage means the total cost to run the full Intelligence Index on GPT-5.5 (xhigh) is only about 20% higher than its predecessor. More notably, GPT-5.5 (xhigh) is approximately 30% cheaper to run the full index than Claude Opus 4.7 (max), and GPT-5.5 (medium) delivers an equivalent benchmark score at roughly one-quarter the cost (~$1,200 vs. ~$4,800).
However, the headline-grabbing benchmark scores come with important caveats. GPT-5.5 (xhigh) exhibited a hallucination rate of 86% on the AA-Omniscience factual knowledge benchmark — far higher than Claude Opus 4.7 (max) at 36% — meaning it frequently provides confidently incorrect answers. Additionally, on SWE-Bench Pro, which tests real-world GitHub issue resolution, GPT-5.5 scored 58.6%, falling short of Claude Opus 4.7's 64.3%, though questions about data contamination in that benchmark complicate the comparison.
Fact Check
Evidence from both sides
Supporting Evidence
GPT-5.5 (xhigh) leads the Intelligence Index at 60
Artificial Analysis, the organization behind the benchmark, explicitly confirms that GPT-5.5 (xhigh) achieved a score of 60 on their Intelligence Index v4.0, making it the highest-scoring model and the first to break out of the 50s range.
GPT-5.5 (high) scored 59, meaningfully ahead of prior SOTA
Artificial Analysis data confirms GPT-5.5 (high) scored 59 on the index, placing it two points above the previous top score of 57 shared by multiple models.
GPT-5.5 (medium) is tied for SOTA at 57
Artificial Analysis reports that GPT-5.5 (medium) scored 57, matching Claude Opus 4.7 (max) and Gemini 3.1 Pro Preview, which confirms the tweet's claim that the medium variant is tied for the previous state of the art.
Multiple independent sources confirm the release
OpenAI's own announcements and multiple independent news outlets corroborate the April 23, 2026 release of GPT-5.5 and its availability across ChatGPT and Codex for Plus, Pro, Business, and Enterprise subscribers.
Enhanced agentic capabilities broadly documented
OpenAI's documentation and independent analyses highlight GPT-5.5's significant advancements in agentic coding, computer use, knowledge work, and early scientific research, supporting the narrative of meaningful progress beyond benchmark scores alone.
Contradicting Evidence
Alarmingly high hallucination rate of 86%
On the AA-Omniscience factual knowledge benchmark, GPT-5.5 (xhigh) exhibited a hallucination rate of 86%, described as "shockingly high" — far exceeding Claude Opus 4.7 (max) at 36% and Gemini 3.1 Pro Preview at 50%. This significantly nuances the SOTA claim by revealing that the model confidently fabricates answers when it lacks knowledge.
Underperformance on SWE-Bench Pro coding tasks
GPT-5.5 scored 58.6% on SWE-Bench Pro, which evaluates real-world GitHub issue resolution, while Claude Opus 4.7 achieved 64.3% on the same benchmark. Although OpenAI flagged potential memorization issues with Claude's results and some researchers question the benchmark's validity at the frontier, this is a notable area where GPT-5.5 trails a competitor.
Gemini 3.1 Pro Preview achieves the same medium-tier score for less cost
While GPT-5.5 (medium) is highlighted as cost-effective at ~$1,200 to run the full index, Gemini 3.1 Pro Preview achieves the same score of 57 for approximately ~$900, making it the cheaper option for equivalent benchmark performance.
API access was delayed at launch
OpenAI initially withheld API access for GPT-5.5 citing the need for "different safeguards," limiting immediate developer adoption and raising questions about the model's readiness for production use despite its strong benchmark showing.
Report an Issue
Found something wrong with this article? Let us know and we'll look into it.