🇺🇸 xAI is only using 11% of its insane 550,000 NVIDIA GPUs right now (just ~60k active). Meta & Google are hitting 43-46%. Scaling these monster clusters is still wild; even the best are figuring it out. Colossus is sleeping… for now. Source: @muskonomy https://t.co/BZU14q9WKO
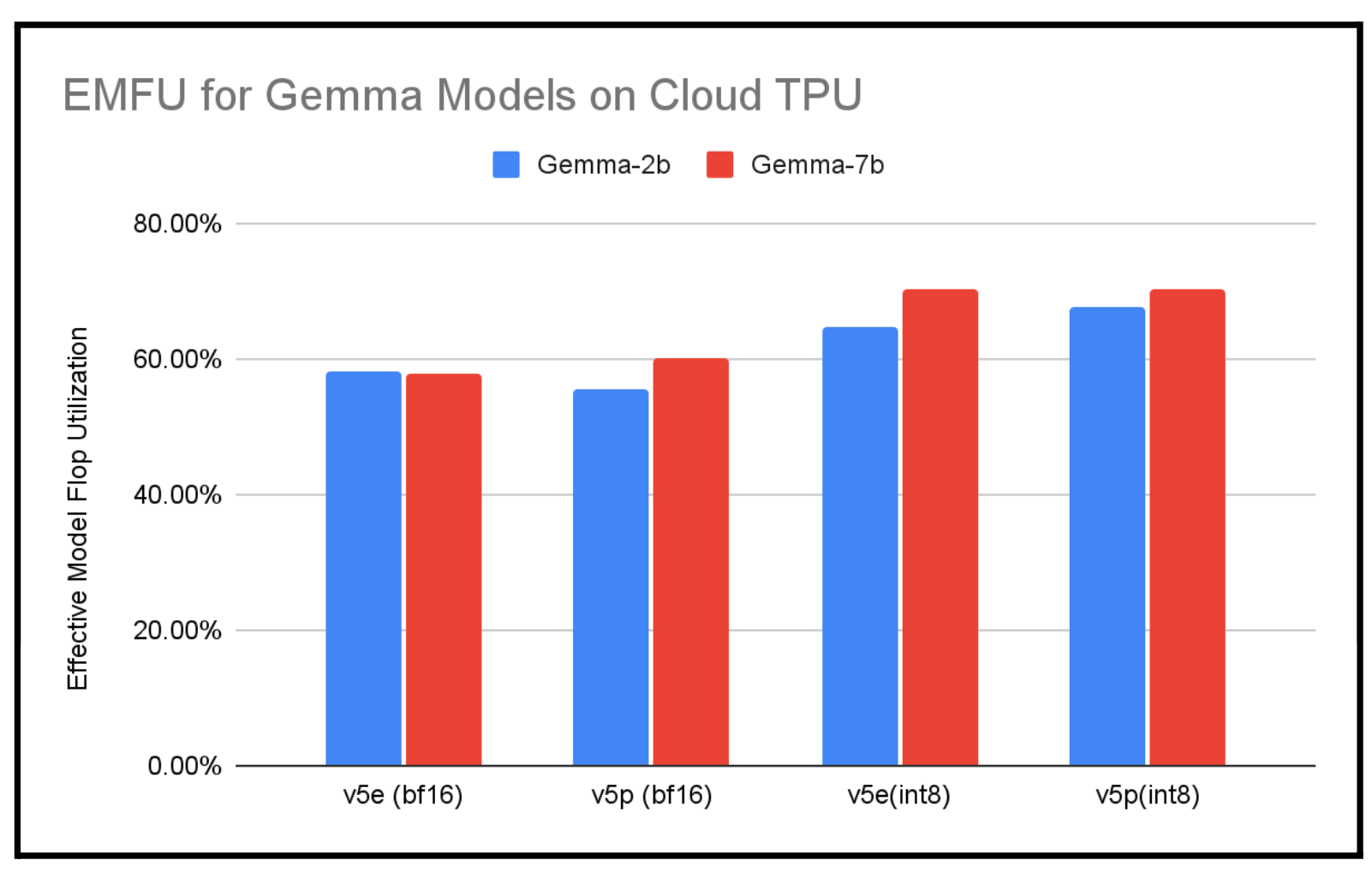
Bar chart titled “EMFU for Gemma Models on Cloud TPU” showing Effective Model FLOPs Utilization (EMFU) for Gemma‑2b and Gemma‑7b across TPU v5e/v5p and precision modes (roughly ~56% BF16 up to ~65–72% for INT8). This visualization (from a reputable Google Cloud performance post) shows that Google’s TPU setups can achieve substantially higher model‑FLOPs utilization than the ~11% reported for xAI, supporting the tweet’s claim that Google (and similarly optimized systems) can reach MFU levels in the 40%+ range.
Source: Google Cloud Blog (Google)
Research Brief
What our analysis found
xAI's Colossus supercomputer, now comprising an estimated 550,000 NVIDIA GPUs — a mix of H100s, H200s, and Blackwell AI accelerators — is one of the largest AI training clusters ever assembled. Yet according to an internal memo first reported by The Information, the facility's Model FLOPs Utilization (MFU) has hovered around just 11% in recent weeks, translating to roughly 60,500 effectively active GPUs. xAI's own president, Michael Nicolls, reportedly called the figure "embarrassingly low," while a rival researcher described it as "appallingly low."
By comparison, Meta and Google have achieved MFU rates of approximately 43% and 46%, respectively — figures that sit at the top end of the typical 35–45% industry range. The gap underscores just how difficult it is to efficiently scale massive GPU clusters, where bottlenecks in data pipelines, inter-node communication, and software optimization can dramatically erode real-world performance. Even Salesforce, working with Google Cloud's managed Lustre, only recently pushed its GPU utilization from about 48% to over 90% — illustrating the engineering effort required.
Despite the low utilization, xAI's Colossus 2 cluster is actively running seven concurrent training jobs for models including multiple variants of Grok 4.x and Grok 5. The company has stated a target of reaching 50% MFU through infrastructure and software stack improvements. Meanwhile, expansion continues at the Memphis, Tennessee facility, with long-term plans to scale to 1 million GPUs and a site power capacity of 2 gigawatts — though satellite imagery from January 2026 suggested the facility had only 350 MW of cooling capacity, well short of interim targets.
Fact Check
Evidence from both sides
Supporting Evidence
xAI's 11% MFU confirmed by internal memo
Multiple reputable outlets, citing a report by The Information and an internal xAI memo, confirm that the company's Model FLOPs Utilization for its GPU cluster was approximately 11% in recent weeks. xAI's president Michael Nicolls himself described the figure as "embarrassingly low."
550,000 GPU count is consistent with recent reports
As of May 2026, reporting indicates xAI is operating around 550,000 NVIDIA GPUs, including H100s, H200s, and Blackwell AI accelerators, aligning with the tweet's stated figure.
Meta and Google utilization rates of 43–46% are substantiated
Industry analyses confirm that Meta and Google have achieved MFU rates of up to 43% and 46%, respectively, placing them at the high end of the typical 35–45% range reported across the AI industry.
Scaling large GPU clusters remains an industry-wide challenge
AI training workloads are inherently "bursty," and most companies struggle to exceed 40% utilization due to data bottlenecks, network overhead, and memory constraints — supporting the tweet's assertion that "even the best are figuring it out."
Contradicting Evidence
MFU is not the same as raw GPU utilization
The 11% figure refers to Model FLOPs Utilization, which measures effective computational output relative to theoretical peak performance. Raw GPU utilization — the percentage of time GPUs are actively processing — can register at 100% even when the work being performed is highly inefficient. The tweet's framing of "only 60k active" GPUs conflates these two distinct metrics.
Colossus is not exactly "sleeping"
Despite the low MFU, xAI's Colossus 2 cluster is actively running seven concurrent training jobs across multiple Grok model variants as of May 2026. The GPUs are engaged, but the effective computational throughput is poor — a meaningful distinction from the cluster being idle.
xAI is actively working to close the gap
The company has publicly acknowledged the low utilization and set a target of reaching 50% MFU through software stack and infrastructure optimizations, suggesting the current figure may represent a temporary state during scaling rather than a permanent limitation.
Industry comparisons require context
While Meta and Google's 43–46% rates are notably higher, these companies have spent years optimizing their software stacks for large-scale training. xAI's cluster expanded from 100,000 to 550,000 GPUs in roughly a year, and the rapid pace of hardware deployment has likely outstripped software optimization efforts — a common pattern in the industry.
Report an Issue
Found something wrong with this article? Let us know and we'll look into it.