New on the Science Blog: We gave Claude 99 problems analyzing real biological data and compared its performance against an expert panel. On 23 problems, the experts were stumped. Our most recent models solved roughly 30% of those—and most of the rest. https://t.co/BYqr76zxhk
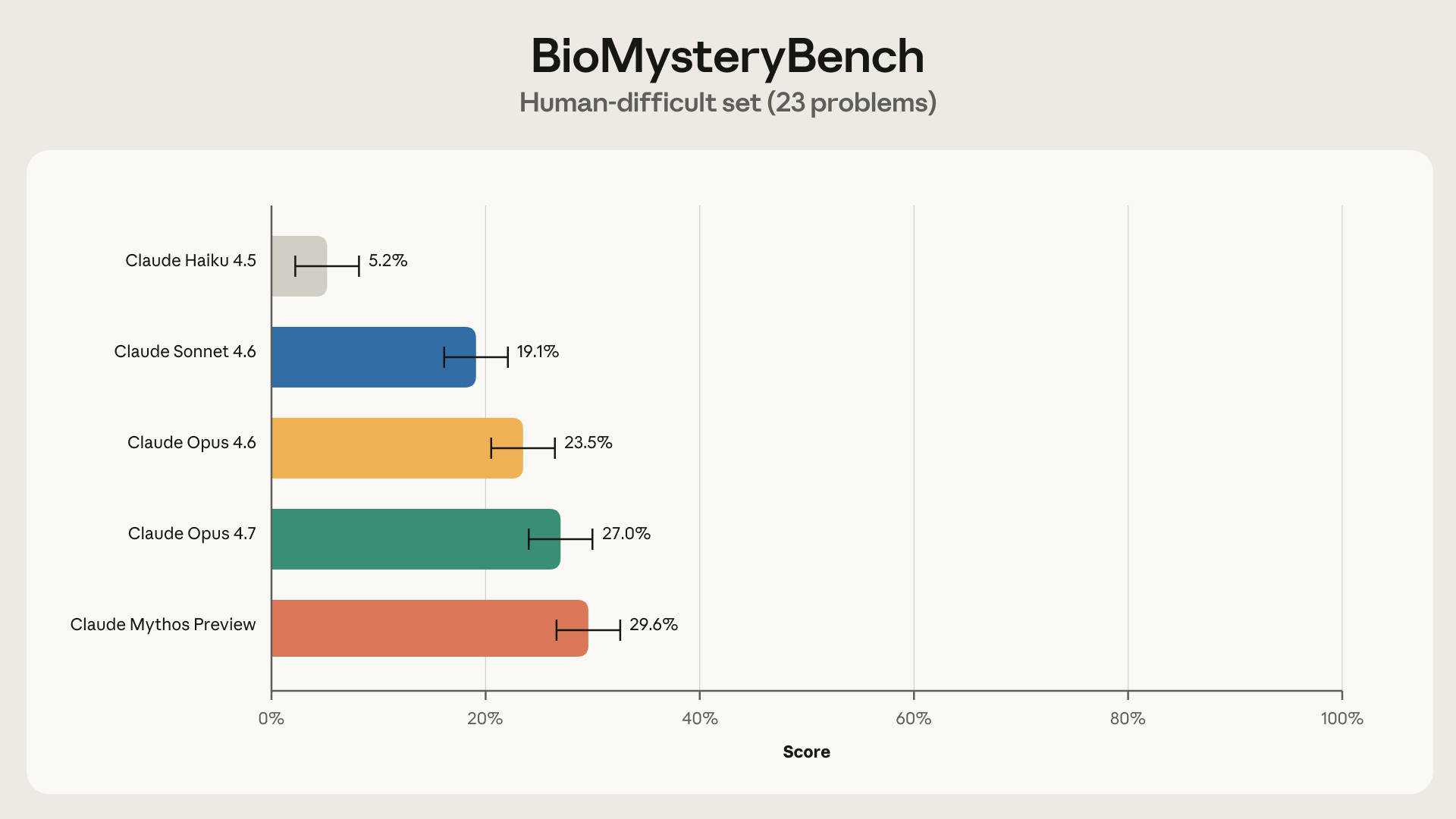
Bar chart from Anthropic’s BioMysteryBench post showing model accuracy on the 23 "human‑difficult" problems; it lists each Claude model’s solve rate (Claude Mythos Preview ≈29.6%), directly illustrating the tweet’s claim that recent Claude models solved roughly 30% of the problems that stumped the expert panel.
Source: Anthropic (Research / Science Blog)
Research Brief
What our analysis found
Anthropic launched BioMysteryBench on April 29, 2026, a benchmark comprising 99 questions drawn from diverse fields of bioinformatics and crafted by domain experts using real-world datasets. Of those 99 problems, 76 were classified as "human-solvable" — meaning at least one expert on a panel could answer them — while 23 were deemed "human-difficult," stumping an entire panel of five domain experts. Anthropic's most recent model at the time, Claude Mythos Preview, solved roughly 30% of the 23 human-difficult problems and performed comparably to human experts on the remaining tasks, with an overall accuracy of 82.6% on human-solvable questions.
The results were independently corroborated by Genentech and Roche's CompBioBench, released concurrently, which found Claude Opus 4.6 achieving 81% overall accuracy and 69% on their hardest questions. However, important caveats emerged: on human-difficult problems, only 44% of Claude's correct answers were consistently reproduced across multiple attempts, compared to 86% consistency on human-solvable tasks. This suggests some breakthroughs on the hardest problems may reflect fortunate reasoning paths rather than reliably reproducible scientific analysis.
The benchmark gave Claude models access to a containerized environment with canonical bioinformatics tools, the ability to install additional software, and connections to databases such as NCBI and Ensembl. Anthropic has acknowledged limitations of the benchmark, noting that for problems neither humans nor AI have solved, it remains unclear whether they are truly impossible or merely extraordinarily difficult. Experts, including Fields Medalist Timothy Gowers, have emphasized that while AI can greatly accelerate research, human oversight remains essential.
Fact Check
Evidence from both sides
Supporting Evidence
Anthropic's official blog post confirms the core claim
The Science Blog entry titled "Evaluating Claude's bioinformatics research capabilities with BioMysteryBench," published April 29, 2026, details the 99-problem benchmark, the 23 human-difficult questions, and the approximately 30% solve rate by Claude Mythos Preview — directly matching every figure cited in the tweet.
Independent news outlets corroborate the results
Articles from Phemex and OfficeChai, published on April 30, 2026, independently reiterate the key performance metrics, including the 30% solve rate on human-difficult problems and comparable expert-level performance on human-solvable tasks.
Genentech and Roche's CompBioBench provides independent validation
A concurrent benchmark from Genentech and Roche found Claude Opus 4.6 achieved 81% overall accuracy and 69% on their hardest problems, lending outside credibility to Anthropic's claims about frontier AI capabilities in bioinformatics.
Prior benchmark history supports a trajectory of improvement
Earlier Anthropic communications from October 2025 and March 2026 documented Claude's continuous improvement on bioinformatics benchmarks such as Protocol QA and BixBench, as well as its completion of a genome-wide association study in 20 minutes — a task that typically takes humans months.
Contradicting Evidence
Inconsistent problem-solving on hard questions raises reliability concerns
While the tweet highlights Claude solving 30% of human-difficult problems, only 44% of those correct answers were consistently reproduced across five attempts. So-called "brittle wins" — problems solved only once or twice in five tries — accounted for 44% of its successes on hard problems, suggesting some results may stem from lucky reasoning paths rather than robust scientific capability.
Anthropic acknowledges inherent benchmark limitations
For problems that neither humans nor AI models have solved, Anthropic admits it is difficult to determine whether those questions are truly impossible or merely extraordinarily difficult. Validation notebooks ensure the underlying data contains a signal, but they cannot guarantee an answer is discoverable from scratch.
Real biological data remains inherently messy and subjective
Despite BioMysteryBench being designed for objective, verifiable answers, the broader challenge of biological data subjectivity persists — different research decisions applied to the same dataset can yield varied conclusions, which complicates the interpretation of AI performance.
Experts caution that AI still requires human oversight
Fields Medalist Timothy Gowers stated that while AI can "greatly speed up" research, "AI still needs us," tempering any suggestion that these results indicate full autonomy in scientific discovery.
Dual-use risks accompany improved biological AI capabilities
The same capabilities that make Claude effective at bioinformatics research also reduce the expertise barrier for potential misuse in biology, a concern Anthropic itself flags alongside the performance results.
Report an Issue
Found something wrong with this article? Let us know and we'll look into it.